

Some of you might find it odd that I made a separate post to talk about the settings in the Advanced tab of Handbrake. But rest assured, there’s a damn good reason why I chose to do so. The first tutorial was targeted at beginners. In essence, I’d say that the first tutorial was 80% handbrake and 20% some general info about videos and encoding. This tutorial would be about 20% Handbrake and 80% x264 video encoding and compression, as you need to know a fair bit about how x264 encodes video to completely understand the options in this tab.
- 1. x264 Video Encoding
- 2. Advanced Tab
- 2.1. Encoding
- 2.1.1. Reference Frames
- 2.1.2. Maximum B Frames
- 2.1.3. Pyramidal B Frames
- 2.1.4. Weighted P Frames
- 2.1.5. 8×8 Transform
- 2.1.6. CABAC
- 2.2. Analysis
- 2.2.1. Adaptive B Frames
- 2.2.2. Adaptive Direct Mode
- 2.2.3. Subpixel Motion Est(subme)
- 2.2.4. Motion Est Method
- 2.2.5. Motion Est Range(merange)
- 2.2.6. Partition Type
- 2.2.7. Trellis
- 2.3. Psychovisual
- 3. Closing Notes
Before going any further, let me make this clear; most users won’t need to mess around with these settings. The settings in this tab are just for those few users who like to tweak and fine tune the encoder’s settings for the video. You can get a decent output without using this tab.
x264 Video Encoding
x264 is, as of now, the most popular and widely regarded as the best video encoder out there. No other encoder comes close to it in terms of quality at a given bitrate, and it is compatible with most devices too. Let us see now what it is that makes this codec so good.
Eliminating Redundancies
To those who dont know the various redundancies that exist in a video and why eliminating them is important, check out: Video Redundancies .
To eliminate spatial and temporal redundancies, each macroblock in a frame is scanned first to identify the redundant information. These redundant information are then predicted by using various algorithms and are replaced by the “predicted” blocks, which ultimately results in a much smaller file size. Two kinds of prediction are used by x264 to predict the macroblocks in a frame:
- Intra Frame Prediction: Macroblocks are predicted by using previously encoded data in the current frame. This is used for eliminating spatial redundancies. A prediction for the current block is formed from the previously encoded neighbouring blocks.
-
Inter Frame Prediction: Macroblocks are predicted by using previously encoded data in the neighbouring frames. This is used for eliminating temporal redundancies. It is also known as Motion Estimation. This prediction is done by scanning the corresponding block that is already encoded in the neighbouring frames. The similar blocks are considered to be the static part of the scene(the “background”), while the differing blocks are collectively considered to be the active(“moving”) part in the scene. The output is then, a video that is comprised of reference frames, which contains the static and active parts, and predicted frames which consists of the moving parts overlaid on the background to recreate the scene, frame by frame.
So basically, what happens here is that the static parts in the scene are copied as it is from the reference frame to the predicted frame. And for the active parts, a motion vector is calculated to change their position from that of the reference frame to that of the predicted frame. This process is called Motion Compensation. So, the predicted frame, in this sense, directly or indirectly depends on the reference frame, and would take up much less space than what it would if the entire frame was stored.
H.264 standard defines 3 types of frames that can be used by the codec. These are:
- I Frame: I frame (Intra Frame) is nothing but the frame copied as it is from the source. It is completely independent of other frames in the video stream, and can be decoded without reference from the other frames. The frame is encoded by using only Intra Frame Prediction. The more the number of I frames in the video, the better the quality, but the lower the compression. I frames are used in H.264 in the start of the video file or in a rapid scene change.
- P Frame: P Frames(Predicted Frames) are frames that are dependent on previous I or P frames. These frames only hold the information about the moving part in the scene, by using Inter Frame Prediction. On an average, it can be said to contain about 50% the information contained on an I frame.
- B Frame: B Frames(Bidirectional Predicted Frames) are frames that are dependent on both previous as well as future I and P frames. These frames, similar to P frames, only hold the information about the moving part in the scene. On an average, it can be said to contain about 50% the information contained on a P frame.
The way the encoder arranges these frames together is called GOP(Group Of Pictures), starting with the I frame at the beginning. This, in turn is made up of mini GOPs beginning with a P/B frame. Now, consider an I frame to be of size x, a P frame 0.5x, and B frame 0.25x. For the following GOPs:
IIII: Size=4x
IPPP: Size=2.5x
IBBP: Size=2x
The advantages of using predicted frames are quite evident from the above example.
Once the predicted frames are formed (by either Intra or Inter prediction), each block in it is subtracted from the ones in the actual frame to form the residual block. These residual blocks are then transformed using either order 4 or order 8 integer transform to output a stream of coefficients for each block. The transformed coefficients are then quantized, ie, scaled by a value obtained from the Quantization Parameter(QP). The basic idea is to reduce the value of the coefficient as much as possible. The QP defines by what extent each block is to be compressed. Higher QP values mean more compression but lower quality, and lower values mean less compression but higher quality. The quantized blocks are then entropy coded to finally obtain the output video file. This is a form of lossless compression method that is done at the end, to eliminate the coding redundancies.
Rate Factor vs Quantization Parameter
One difference that you can observe when encoding videos (in Handbrake) using x264 in Constant Quality mode is that; while all other codecs will offer you a QP (Quantization Parameter) Slider, x264(and x265) will offer you an RF (Rate Factor) Slider. There is quite an inherent difference between the two.
Constant Quality encoding can be achieved by two ways:
-
Constant Quantization Parameter (CQP): In this method, constant quality is achieved by compressing every frame of the same type by the same amount, ie, a constant QP is maintained for the entire video. So, if the QP slider is kept at 24, it will remain 24 for the entire video.
The QP slider scale is linear, and the output filesize would change linearly with the QP value.
-
Constant Rate Factor (CRF): In this method, the QP is not kept constant throughout the video, but will be variable. Thus, different frames are compressed by different amounts, depending on the amount of detail and motion on the frame. CRF takes advantage of the simple fact that the eye perceives more detail in stationary objects than in moving objects. So, it applies more compression for fast motion scenes, and less compression for still scenes. Due to this, the output video will appear to be much more detailed. So, if the RF slider is kept at 24, then the QP might range from around 26-18.
The RF slider scale is logarithmic, and the output filesize would change exponentially with deviation of the RF value.
So, which of these is better? Obviously CRF, as it can distribute bits in a much more efficient way than CQP.
Advanced Tab
The settings within this tab are unlocked by checking the “Use Advanced Tab instead” option in the Video tab. These settings allow you to fine tune your video by adjusting the various conversion parameters of the x264 codec. This tab is further subdivided into three sections: Encoding, Analysis, and Psychovisual.

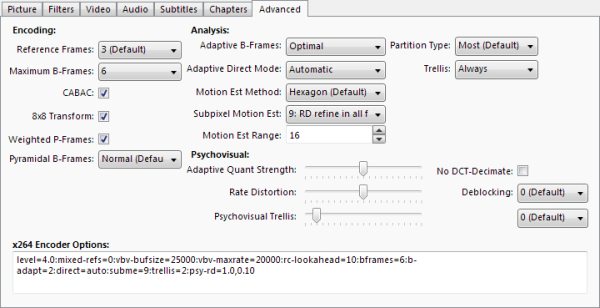
Handbrake Advanced Tab
Encoding
The Encoding section deals with video compression. It offers various ways by which your video bitrate could be further reduced.
Reference Frames:
This setting specifies the maximum number of frames each P frame can use as a reference. The higher this value, the better the compression. But it must be noted that many devices have limitations on the maximum number of reference frames that can be used. So, unless your sure what this value is, keep it at default(3).
Maximum B frames:
This setting allows you to set the maximum number of successive B frames that can be encoded, after which an I or P frame has to follow for reference.
Pyramidal B frames:
Enabling this setting allows the B frames to be used as reference for other B frames wherever possible, thereby increasing compression. Options of None, Normal and Strict are provided.
- None: B frames are not used as reference.
- Strict: One B frame per mini GOP can be used as reference
- Normal: Numerous B frames per mini GOP can be used as reference.
Weighted P Frames:
Enabling this option allows the encoder to detect fades in reference frames, and assign it a particular weight. If this is OFF, the encoder will be unable to see the similarity between frames in cases where a frame is simply lighter or darker from the previous frame, as the entire frame is changing. Turning this ON can improve compression in such cases.
8×8 Transform:
Enabling this option allows the use of 8×8 blocks, rather than the normal 16×16 blocks, for prediction. This can improve compression by quite a lot(at least 5%).
CABAC:
After quantization, the data stream has to be encoded. x264 offers two methods to achieve this: CABAC(Context Adaptive Binary Arithmetic Coding) and CAVLC(Context Adaptive Variable Length Coding). CABAC offers better compression, but requires more processing power to encode and decode than CAVLC. CAVLC, on the other hand, offers inferior compression, but requires less processing power to encode and decode than CABAC.
To turn ON CABAC encoding, tick the “CABAC” checkbox. Unchecking it will use CAVLC encoding, by default.
Analysis
This section contains settings using which you can control how x264 analyzes the source video.
Adaptive B frames:
Using the options in this setting, you can control how x264 makes the decision to use a B frame.
- OFF: B frames will be placed in a fixed pattern.
- Fast: x264 can decide how many B frames to use depending on the complexity of the scene, but the decisions made are suboptimal.
- Optimal: x264 makes an optimal decision on when B frames are to be used. When using a higher number of Maximum B frames with Pyramidal B Frames, it is recommended to use this setting.
Adaptive Direct Mode:
This setting specifies how motion vectors are calculated for each block. Calculating motion vectors for every block is a CPU intensive and time consuming process. x264 has a few tricks up it’s sleeve for this.
- None: Adaptive Direct Mode is disabled. Motion Vectors have to be calculated for each block.
- Spatial: Motion vectors from the neighbouring blocks are used for the current block. This can significantly reduce the encoding time.
- Temporal: The current block is compared with the matched block in a P frame within the GOP. Using this, the motion vector is estimated rather than calculating it for each block.
- Automatic: x264 automatically chooses whether to use Spatial or Temporal for each block.
Subpixel Motion Est(subme):
One of the things that make x264 far superior to other codecs is it’s amazing Motion Compensation capabilities. x264 even supports estimating the motion of a block by a non integer number of pixels, which is called Subpixel Motion Estimation. The advantages that this offers are quite obvious.
- SAD(Sum of Absolute Differences): In this, the absolute differences between the pixels in the current block and the corresponding pixels in the block to be compared are taken, and are then added to obtain an SAD value. The block which gives the lowest SAD value will be the considered to be the block using which the motion vector will be calculated. This method can be used either with no Subpixel Motion Estimation(subme 0), or with one iteration of Quarter Pixel precision(subme 1).
- SATD (Sum of Absolute Transformed Differences):Similar to SAD, with the only difference being that the differences of each pixel is frequency transformed before being added. Although this is much slower than SAD, it gives a much better prediction. This method can be used with two iterations of Quarter Pixel precision(subme 2), one iteration of Half Pixel precision interpolated to give quarter pixel precision(subme 3), always with Quarter Pixel precision(subme 4) and with Quarter Pixel precision + Bidirectional Motion Estimation(subme 5).
- RD(Rate Distortion): The disadvantage of using SAD/SATD is that, many a time, the number of bits used for representing a sample would be more than what is actually needed. This could drastically increase the output file size, especially when using Quarter Pixel Precision.
RD rectifies this issue by measuring the distortion D and the the number of bits R required for each decision, and comparing these with a cost function to make the mode decision. This can be used in either I/P frames(subme 6) or in all frames(subme 7). - RD Refine: In this setting, RD is used to refine both motion vectors and mode decisions. This again, can be used in either I/P frames(subme 8) or in all frames(subme 9). This is slower than normal RD, but more efficient.
- QPRD(Quarter Pixel Rate Distortion): This setting does an RD optimization on some quarter pixels using a hexagonal search(subme 10). First, the SATD is checked. If this is found to be above the threshold value, then the RD process is skipped. If the SATD is below the threshold value, then RD is used. This process much slower, and requires trellis to be set at 2 and Adaptive Quant Strength > 0.
Motion Est Method:
x264 has a variety of search patterns for estimating how each block of pixels have moved in successive frames.
Key:

-
Diamond:
Pattern:
Searches similar pixels in a Diamond pattern. This is the fastest method, however the results obtained are the most inferior.
-
Hexagon:
Pattern:
Searches similar pixels in a Hexagon pattern. Slower than Diamond search, but produces much better results.
-
Exhaustive:
Pattern:
Searches similar pixels in a wide area(directly given by the Motion Est Range) surrounding the current pixel. This is an extremely slow pattern, and in most cases, the compression gain offered by this is just not worth it.
-
Transformed Exhaustive: It is similar to exhaustive, but is slightly better and slower.
-
Uneven Multi Hexagon: This makes use of five different search patterns; Unsymmetrical cross search, Small rectangular full search, Uneven Multi Hexagon grid search, Extended Hexagon based search and Diamond search. Based on the complexity of the scene, x264 will choose one or multiple of these patterns to estimate motion. Like exhaustive, the range of this search is directly controlled by the Motion Est Range. This is slower than Hexagon search(faster than Exhaustive), but gives much better results in scenes with complex motion.



Motion Est Range(merange):
This value specifies the maximum range in pixels that the encoder searches for a match. For Diamond and Hexagon pattern, this value ranges from 4-16. For Uneven Multi Hexagon and Exhaustive, this value can be extended beyond 16, which can be particularly useful for high motion scenes.
Partition Type:
Each macroblock is broken down to form prediction blocks by the x264 encoder. There are 6 possible ways by which this can be done;
- Intra Macroblock: 16×16, 8×8
- Inter Macroblock: 16×16, 16×8, 8×16, 8×8
- The 8×8 blocks can further be broken down into even smaller blocks.
Each of these partitions are then represented using separate motion vectors. This partitioning is called mode.
A macroblock with less partitions would require lesser motion vectors to represent its motion. However, these motion vectors might not accurately represent the motion, resulting in a large error and hence encoding the error would require more bits. Similarly, more partitions would require more motion vectors to represent the motion information and fewer bits to encode the residual error.
The mode selection for each macroblock is one of the steps which contributes to x264s ability to give a great quality output at a low bitrate, but it is a time consuming process, especially if more macroblocks are partitioned.
By using the options in this setting, you can control how many macroblocks the encoder will partition. Options of Most, None ,Some and All are provided.
Trellis:
Enabling this setting allows x264 to use trellis quantization algorithm for rounding off the transformed coefficients, which can improve compression by a bit. CABAC must be enabled to use this. You can choose to use this either for encoding only or always(for both analysis and encoding). Choosing always can hit your encoding speed.
Psychovisual
Using the settings in this section, you can control the extent to which the encoder will remove psychovisual redundancies.
No DCT Decimate:
DCT Decimation allows the x264 encoder to skip encoding any of the blocks which it views as redundant information. These blocks are the not written to the output file, effectively reducing the bitrate. Checking this option will prevent x264 from skipping such blocks. This is useful if you want to preserve the grain in your videos, which are otherwise removed by DCT decimation.
Adaptive Quant Strength:
Adaptive Quantization is the process of using a different value quantizer for each block. As x264 uses CRF for constant quality(in Handbrake), this setting can be used to control how x264 distributes bits between the flat areas and the complex areas in the frames.
Higher values(>1) means more bits are allocated to the flats than to the complex areas in a frame, effectively reducing the banding artifacts, but causing some ringing artifacts. Lower Values(<1) means more bits are allocated to the edges in a frame, effectively reducing the ringing artifacts, but causing some banding artifacts.

Banding Artifacts: Discontinuities in the Gradient inside the circle and in the background.
Psychovisual Rate Distortion:
This setting adjusts the tradeoff between detail retention and actual video quality(the way the computer sees it). Higher values tend to retain the finer details(grain) at the expense of some loss in quality(undesirable blocking artifacts). The encoded video will thus, appear sharper and more detailed as compared to what it would have been if this was set to 0. To use this, subme should be 6 or higher.
Psychovisual Trellis:
This setting can be used to improve the sharpness and retain details by varying the strength function of the trellis quantization algorithm. The slider works similar to the Rate Distortion Slider. Higher values bias the finer details over the quality.
Deblocking:
Does the same thing as the Deblocking Filter in the “Filters” tab, but in a much better way. There are two parameters that you could give as input to x264’s deblocking filter: Alpha and Beta. Alpha value control the amount of deblocking to be applied; higher values would give a softer image. Beta value is the threshold value with which the block is first compared before it is deblocked.
Closing Notes
Well, thats all there is to encoding videos using Handbrake. Always make it a practise to encode a preview first and try playing it on your intended device. Video encoding does take a lot of time, and you wouldn’t want to be that fool who spends hours encoding the entire video just to find that it doesn’t work on your device.
Apart from that, have fun encoding! Hope you found this tutorial helpful.