

War on GPU’s

Graphics Cards :
The choice of this component is actually the most tricky and we see more discussions about this higher than anything else in the communities. Better FPS or smoothness, Compute Performance or raw performance, single GPU or multi GPU setup you name it and we will find war like situations over it.. In my articles I will try to give you a brief overview of some very important features and concepts regarding graphics processing in general and in turn Graphics Cards.
Please read on to know more..
Frame rates, gaming latency and discarded frames
So what exactly are this technological jargon’s?
FPS or Frames Per Second: It is the most common technique of measuring performance and most review sites actually stress on this parameter only. Now better FPS is always better in most cases but now we know there are certain catches.
Gaming Latency: is very important while playing games as it decides how responsive the GPU is between the input from the player and the effects to take place. Sometimes it is noticed that even full frame rate is maintained, the game lags if very high amount of post processing is being applied. However, in 1080P, this latency is almost negligible in current gen Graphics cards of same league.
Discarded Frames: These days most of the Monitors are 60 Hz and it is impossible to see more than 60 FPS in real time. Then why we are opting for cards which can deliver over 100 FPS sometimes? There is a effect called Plummeting in Gaming, which reduces the smoothness, despite having 60FPS on average. Now here the extra FPS comes to rescue. By using the discarded Frames (Display can show only 60 frames in 1 sec and assuming 90 Frames are available from the Gfx card) and a simple algorithm, GPU can enhance the output frame quality to provide a smooth game-play experience as well as very good Motion Blur effects. AMD has an upper edge here as it is observed in several reviews that Game Play experience become smoother with the increase of FPS in games. I expect that they will add new algorithm in their upcoming drivers to take the advantage of it for reducing Gaming latency.
Compute performance
Now comes the biggest debate between compute performance and gaming performance. Allow us to clear the air on this matter a bit. First we will discuss what is compute performance and how it works and then we will do the same on gaming performance and the difference between the two if any.
What is Compute Performance in GPU?
Initially GPUs are made to play computer games and after 2 decades, their main purpose is same. They are special purpose processing units built to handle large number of pixels in parallel by performing two main tasks, Pixel Shading and Vertex Shading. After the unified shader architecture is adopted in GPU architecture, starting from Nvidia 8000 and AMD HD 3000 series, GPU business shows many different aspects apart from gaming. Before this, GPU used to consist of several Pixel Shader and Vertex Shader units; the former performing different pixel operations whereas the later performing the coordinate related calculations.
But in Unified shader model, there is a single unit, which we know as Stream Processor, is capable of doing both Vertex and Pixel operations and a GPU has many of them, resulting a huge parallel processing of vertex and pixel. Each of those units has its own resources like execution unit, Registers, Cache etc. Now GPU can be viewed as a SIMD or Single Instruction Multiple Data Model, where a single instruction can be performed over a huge number of data in parallel. This resembles to the traditional design of vector processors which do have simple but large number of execution units to perform a single operation over a large dataset.
Consider the following Pseudo code:
int a[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int b[10] = {11, 12, 13, 14, 15, 16, 17, 18, 19, 20};
int c[10];
for (int i = 0 to 9)
{ c[i] = a[i] + b[i]; }
In the above example,
- a and b are two single dimensional array and each of them are holding 10 elements.
- For an array, the values of it are stored in contagious memory location. Say, the values of a are stored in main memory or Ram in the location from 101 to 110 (Ram is divided into huge number of memory blocks, each of them having same capacity.) and for b, it is 201 to 210.
- For c, Memory space is allocated starting from 301 and ends at 310. They are just initialized and not containing any value.
Now if you look at the for loop in the code, you will see that there are 10 ADD instruction and each instruction is operating over a different set of values; different values of a and b.
This is exactly how a conventional CPU will see.
So here how it will be executed in our CPU:
Set Counter to 0
LOOP 10 times
Fetch the instruction c[i] = a[i] + b[i];
Decode the instruction;
Fetch the value of a[counter] from Memory Location 101+Counter (101 is the base address of a) into Register A;
Fetch the value of b[counter] from Memory Location 201+Counter (201 is the base address of b) into Register B;
Store the value of a[counter] + b[counter] into Register C;
Write the result in Memory Location 301+Counter (301, base address of c);
Counter = Counter +1;
End Loop
So here CPU is basically looping 10 times, i.e., the size of the array, getting the instruction of addition each time, fetching the values of a and b for that iteration, adding them and storing the result back to the memory location, allocated for C in that iteration. But if you look closely, you will find that we are actually having single instruction which operates over 10 set of data, not 10 separate instructions. This thing can be fasten by use of Pipelining by overlapping the instructions but true parallel processing is not here. Also Multicore CPU is not going to help much as this whole thing is not going to create multiple thread, instead will be allocated to a single Core of the CPU.
Now how a Vector Processor will do it…we are going to see:
Unlike normal CPU, a Vector Processor has multiple execution units and unlike a normal CPU register which can hold only a single data, a Vector register can hold multiple Data. So consider our hypothetical Vector Processor given below, having the following components:-
Instruction Queue:- Instruction queue holds the instructions to be executed sequentially. But unlike a Scalar CPU where each instruction operates over a single dataset, here each instruction operates on multiple data item.Vector Execution Units:- Here we have 10 execution units, each of them can perform a single operation over a single set of data. Hence 10 of them can perform a single operation over 10 dataset.
Vector Fetch and Decode Unit:- This unit fetch and decode the data required for vector operation. But unlike a traditional CPU which fetch a single data, vector fetch unit fetches a whole vector or the whole set of data, over which the vector operation needs to be performed.
Scalar registers: Vector processor does have a set of scalar registers (in our case, it is three) and each of them can hold a single data. Here we are using those registers for holding the start address of the Array a, b and c respectively.
Program Counter: Program Counter holds the address of the next data to be fetched. Here it is holding the length of the Vector which is 10 in our case.
Scalar ALU (Arithmetic Logical Unit): It is basic execution unit which can execute one arithmetic instruction over a single set of data at a time, like a conventional CPU execution unit. It is used to execute instructions which need to be performed over a single dataset to save precious vector execution units. It also helps to verify different conditional statements. Here we are using it to generate the end address of array a and Array b by performing addition of the start address of the array (101 in case of a, 201 in case of b) and the vector length, 10 in our case.
Vector Write Unit: It writes a whole vector to memory as a whole, unlike a normal CPU write where each of the elements needs to be written sequentially. In our case, it is getting the starting location of Vector C and the end location from Program Counter and performs the write operation, writing all the values of C vector to the memory locations, allocated for Array c.

Here goes the Algorithm for Vector Execution:
- Get the Starting address and length of a array and b array
- Set Program Counter to 10, i.e. length of those arrays
- Fetch memory address 101 to 110 into Vector Register A. Now A has all the
values of a Array.
- Fetch memory address 201 to 210 into Vector Register B. Now B has all the
values of B Array.
- Perform Vector C = Vector A + Vector B in a single iteration
- Save the results back to memory location 301 to 310, i.e. the memory allocated
to c Array
You can understand here that instead of looping 10 times a Vector Processor performs the addition operation over 10 data simultaneously.
This model is similar to SIMD model discussed earlier and that is the reason modern day GPUs can be programmed to operate as Vector Processors.
- Each Stream Processor of a GPU are capable to perform a single operation independently. So multiple of them can be used as multiple execution units of Vector Processors.
- Stream Processors are programmable through software and therefore can emulate SIMD design.
- GPU has very fast memory and very wide Memory Bus (384 bit, 256 bit for high end) and can provide huge memory bandwidth which is very much essential for Vector operations as it needs the whole dataset for a vector, unlike single data in single iteration.
But the problem here, unlike CPU, GPU supports very specific type of tasks through hardware. On the other hand, CPU support huge set of generic instruction set which help the programmers huge flexibility during coding. CPU supports complex instructions or Macro codes which will automatically divided into smaller instructions in execution time but programmer does not need to worry about it. That is not in case of GPU where programmer itself has to perform several smaller operations to implement a complex instruction and again, that will be different for different architecture.
But the scenario is changing as multiple API and Program Libraries are coming into the picture to reduce the liability from the developers. CUDA, OpenCL, OpenAL, DirectCompute etc are the example of widely used Libraries. These API models targets the SIMD model of GPU and apart from CUDA, other can implement generic code path for all the different GPU design. Even CUDA’s limitation is rather superficial than technical as it shares a lot from OpenCl.
Now lets read up a few points about Gaming performance.Next page please .
Gaming Performance and its relation to compute performance
On What does Gaming performance depends on?
Gaming performance depends of many factors : memory bandwidth, number of shader processors, Number of ROPs and their performance, Texture handling capabilities.
The conventional gaming approach basically stresses upon Vertex Shader and Pixel shader performance as GPU can perform a single operation over millions of pixels in parallel.
In conventional way, all the gaming effects like Ambient Occlusion, Depth of Field, HDR Bloom and Motion Blur can be implemented using Pixel and Texture operations. But the processes are very heavy and older generation GPUs excels over those fields by using their raw parallel processing powers. But now as games are getting more and more demanding in GPU performance for rendering, if all those effects are turned on and executed in conventional methods, that might create a heavy toll over the GPU, resulting poor performance. So smart and efficient techniques are required to implement the advanced effects in a Game.
Are Gaming Performance and Compute Performance are different fields?
In most reviews, we see that Compute performance and Gaming performance are compared as two different faces of a Coin which lead to the believe that those parameters are different and a GPU can excel in one field while doing not so good in other field.
But with the emergence of new API like DirectCompute, OpenCL, CUDA, which can directly access GPU resources like the Stream Processor Clusters, Video Ram, shared memory like a conventional CPU, enables developers to create some advanced models like a Vector Processor type Processing. As a result we can have threads, data structures like Array, Structure and Classes, Object oriented models in GPU p[programming, just like what we do with our CPU with one exception…GPU can process multiple threads at once by parallel processing unlike the sequential execution methodology of CPU.
I will discuss some of the advanced Graphics enhancement techniques , how they have been implemented in conventional way and how GP-GPU computing performance can improve the performance.
Ambient Occlusion or AO:
Definition: Ambient occlusion is a method to approximate how bright light should be shining on any specific part of a surface, based on the light and it’s environment. This is used to add realism.
Here how a surface will be illuminated is not calculated based on a single point source of light, instead it is calculated by studying how the environment and surroundings of that surface interacts with light. So a place surrounding by other objects will be darker even though the light source is same for all of them.
This technique is a Global approach and needs to applied over the whole image rather than applying it on any specific objects.
Z-Buffer or Depth Buffer: In computer graphics, z-buffering, also known as depth buffering, is the management of image depth coordinates in three-dimensional (3-D) graphics, usually done in hardware, sometimes in software. It is one solution to the visibility problem, which is the problem of deciding which elements of a rendered scene are visible, and which are hidden.
Conventional Pixel Shader Approach:
The algorithm is implemented as a pixel shader, analyzing the scene depth buffer which is stored in a texture. For every pixel on the screen, the pixel shader samples the depth values around the current pixel and tries to compute the amount of occlusion from each of the sampled points. In its simplest implementation, the occlusion factor depends only on the depth difference between sampled point and current point.
- For each Pixel present in the image
- Check surrounding neighborhood to see if they form a concave region–(Fit a cone, is it concave or convex). This step is need to check if surroundings of the pixels
- Improved results if normal of the point included in check
![]()
Given a point P on the surface with normal N, here roughly two-thirds of the hemisphere above P is occluded by other geometry in the scene, while one-third is unoccluded. The average direction of incoming light is denoted by B, and it is somewhat to the right of the normal direction N. Loosely speaking, the average color of incident light at P could be found by averaging the incident light from the cone of unoccluded directions around the B vector.
Now there is no smart method available to detect how many surrounding pixels are needed to be taken care of to provide a realistic illumination of point P. Otherwise using Brute force algorithm, the GPU needs to perform 200 texture reads per second which is not possible in real time using current generation hardware. So the following approximation is applied:
- Some Random sample of pixels are taken from the surroundings of the point needed to be illuminated.
- For each of the pixels present in the sample, their depth buffer is read from the texture Buffer of the Graphics card.
- Now using the algorithm mentioned above, the GPU creates an approximate illumination level of the desired point.
Disadvantages:
- Huge I/O cost. Here for each pixel, the GPU needs to access the Z-Buffer or Texture unit to get its Depth value. in case of 1920X1080 Resolution with 60 Fps, where we are taking 100 neighboring pixel samples for each of the pixels, the total number of Z-Buffer read will be 1920X1080 (Total number of pixels in a single Frame) X 100 (Sample Size for each pixel) X 60 (Number of Frames per frame) =12,441,6 X 10^5 which is huge for even the parallel processing power of GPU. Obviously that number is an rough estimation and can be minimized using different techniques, it gives us an idea how it can affect the game play experience.
- As the Sample of neighboring pixels are taken randomly, the output might not be that realistic compared to the compute power it needs and sometime creates an unnecessary shadow effect.
- Here, for parallel processing, we need to rely upon the Texture buffer or Z-Buffer which can hold normally 12 texels per Sp cluster but not taking the advantage of the local registers and Cache Memory of each of the Stream Processors.
- Poor Resource sharing. I guess you guys have already understood that two neighboring pixel P1 and P2, situated very closely will have almost same surrounding pixels in common. So if we can keep the sample values in GPU registers, taken for P1 and 1st check if they are also neighbor of P2 we can actually save the whole sampling thing required for P2. But unlike data in CPU, pixels cannot be directly kept in registers as no information about them is present as the Sampling picks up random set of pixels.
GPU Computing based Approach:
Now 1st we will discuss another algorithm for AO, which uses Ray Tracing.

Local ambient occlusion in image-space: (a) Rays emerging from a point Pmany of which are not occluded (marked red). (b)Rays being constrained within a distance of rfar, with distant occluders being neglected (blue arrows). (c) Pixels as viewed by a camera. C.Neighboring pixels are obtained (marked in green). (d) We de-project these pixels back to world-space and approximate them using spherical occluders (green circles). These are the final approximated occluders around the point P that are sought in image-space. Note that the spheres are pushed back a little along the opposite direction of the normal (−ˆ n) so as to prevent incorrect occlusion on flat surfaces.

In this example we have two sampling points A and B. At position A only a few rays hit the sphere therefore the influence of the sphere is small, at position B a lot of rays hit the sphere and the influence is big what results in a darker color here.
So the algorithm for Compute Shader will be something like that:
- For every pixel in the image, perform Ray tracing and identify the neighboring pixel Samples required.
- Check if the depth value of the selected pixels are already in GroupShared Registers.
- If Yes, then pick the values from them .
- If No, then read the Z-Buffer and place the fetched values in GroupShared Registers
Advantages:
- Using the group shared memory avoids an incredible amount of over-sampling
- It can be filled using the Gather instruction, which further reduces the number of TEX operations
- Each of the SP of the GPU can perform operation for a different pixels in parallel and can have the data kept in Shared Memory or in Group Shared Registers to be accessed by other SP.
- Each of the SP does have their own Cache memory which can be used to keep frequently read data. It helps a single SP to minimize its I/O operations when it moves to the next pixel after finishing the AO calculation for the current one.
I hope this explains how GPU compute performance is actually beneficial for Gaming performance to implement Ambient Occlusion. Crysis is the 1st Game to implement AO but by means of Pixel Shaders and we all know how heavy the game was on hardware. On the other hand most of the latest games like Battleforge, Battlefield 3, Starcraft III etc use compute based AO logic and they run far smoother.
Depth of Fields:
In Photography, film or 3D games, Depth of field can be considered as the distance between the nearest and farthest object, present in the sharper (relatively sharper than the portion of the image which are blurred and can’t be distinguished properly) portion of the image or Frame.
This effect adds realism and Movie like effects in 3D gaming. It also adds a depth sense in the game which we can understand that how far the object is from the Protagonist, who is in the focus of the camera, which is our eyes. How can we forget the creepy feelings in Metro 2033 where we can understand something is moving around in blurred, shabby areas, little far from the source of light but can’t see it properly?

If you look at the above image, then you will see that the palm which is away from the 1st palm which is in focus, is little shorter and little less sharper too. If we continue like this, the palm size will be getting smaller and more blurred and after some time, it will not be visible when our eyes meet the vanishing point. But until then, we can see palms with varying size and varying sharpness.
So, I guess you guys can relate it with the definition I’ve given. Here until the vanishing point, we can consider the image is sharper enough to distinguish different objects. So depth of field will be the distance between the 1st palm which is in focus and the last palm which is blurred maximum but still identifiable.

The area within the depth of field appears sharp, while the areas in front of and beyond the depth of field appear blurry.
How to Implement: To simulate this 3D sense of depth in a 2D image, we need to blurred and resized each of the distant objects in such a way so that our human eye can understand the depth in the image. resulting an 3D depth simulation in our brain. For this we need to apply separate level of blurriness an size to each of the objects in accordance to their distance from the object present in the focus.
Traditional Pixel Shader Based Approach:
1. Create a Blurred (Normally Down-scaled) version of the Frame
2. Get the distances of the Objects to be blurred from the object in focus.
3. Mix the blurred image with the Crisp image based on the distance from the focal plane to create a image version with DoF implemented.
4. Perform the same operation with the output image of the 1st image created with DoF. For each iteration, the output of the previous step will be the Input. The number of iterations depends upon the used algorithm.
5. Consider the output of the last iteration as the final image and discard all the other images
Issues with the Approach:
Although the approach is not an heavy one, it has several issues and couple of them are mentioned below:
1. Fixed blur radius across scene, no variation with depth
2. Artifacts, created due to the DoF algorithm, along the edges are very hard and tricky to remove. It needs significant logic for each thread.
3. Blurring the objects just based on the distance from the focal plane is not a very good method. It ignores the position of the object with respect to a point camera, which is our eyes in Games and the light emitting from them. Even an object is far from the focal point, if it is thermally hot or radiator of intense light then it should not be as blurred as another object with same distance, not radiating any light. For example, a Lamp Post radiates high intensity light and a dark home, situated at roughly same distance from the focal point will be less blurred.
Scientific Algorithm:
Here we need to understand one Optical concept, important in determining the DoF, both in Photography as well as 3D image creation, known as Circle of Confusion. Lets discuss it a little.
Definition from Wikipedia:
In optics, a circle of confusion is an optical spot caused by a cone of light rays from a lens not coming to a perfect focus when imaging a point source. It is also known as disk of confusion, circle of indistinctness, blur circle, or blur spot.
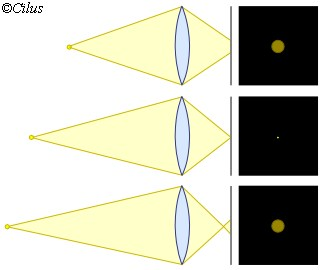
1st Image: Object situated before the focus point of the Lens
2nd Image: Object situated exactly at the focus point of the Lens
3rdImage: Object situated after the focus point of the Lens
In the above image we are describing the property of a perfect Lens which creates a blurred circle of light when a point object is not situated at the focus point. But in reality, no Lens is perfect and the object, situated exactly at the focal plane will create a circle or Spot rather than a single point.
Visual acuity: For most people, the closest comfortable viewing distance, termed the near distance for distinct vision (Ray 2000, 52), is approximately 25 cm. At this distance, a person with good vision can usually distinguish an image resolution of 5 line pairs per millimeter (lp/mm), equivalent to a CoC of 0.2 mm in the final image.

After that distance of 250mm, human eye cannot distinguish between a blurred circle and a very sharp circle that just fills the contact point of two adjoining planes. So Circle of Confusion can be a measure to get the Blur effect to be applied on different objects in an image to simulate a Depth of Field.
GPU Compute Based Solution: Here the algorithm creates a Heat Diffusion based approach to reduce the complexity.
Heat Diffusion Model:
1. The image intensities are taken from a Pin Hole Camera View
2. The heat diffuses or reduces gradually with the distance from the source or the Pin hole Camera (In Games, it is our eye)
3. If it creates an higher Circle of Confusion or having high Blur Radius for object B , it is assumed that the thermal conductivity B is higher and heat will pass through it. It means we don’t need to paint it with sharp color and it will be Blurred when the image will be rendered.
4. Circle of Confusion increases with the distance from the source and as per the radius of the circle, the Blur effect is added to the object proportionately. So we are having objects with variable blur effect.
5. If the Circle of Confusion reaches 0 for an object then it is considered as complete insulator of heat. So it needs to be painted sharply for identifying.
By using this above mentioned Model, several parallel Processing based algorithm can be created which can produce, variable blur effects to different objects, situated at different distances from the focus.
Metro 2033 uses an algorithm known as Alternate Direction Implicit Solver and Hybrid Tri-diagonal Systems Solver which uses two pixel shader passes to create a Blurred version of the image and then perform a DirectCompute based algorithm to generate the final image with vivid Depth of field.
Dynamic Decompression of Textures:
This direct Compute based method is pretty simple compared to the other two, I’ve explained earlier.Suppose I have huge number of documents which are needed to create my final resume and they are scattered here & there in my hard disc and taking a lot of disc space. So what I’ll do, compress all of them in a single Zip or Rar or 7Z file and accessing the part which is needed. If I click on that file, that will be decompressed at run time and will be displayed to me.
There are plenty of games which needs to handle huge amount of textures to render different objects in screen. They might not be very exact but the amount of objects are very high. RTS games like Civilikzation V or StarCraft II are perfect example of it. Here the following DirectCompute based steps are used:
1. Compress the Texture objects into a compressed file and place it to the Video Ram using DirectCompute based parallel processing
2. Dynamically decompress it as per the requirement by using DirectCompute based Decompressing algorithm.
By using this technique, Civilization V can compress texture file of 2GB into a 130MB format which helps it to keep multiple texture files into Video Ram. Now Video Ram can be accessed very fast by GPU due to its high speed and big memory Bus. So it can request the required file which gets decompressed on the fly to produce the final image.In conventional way, the decompressed texture cannot be placed directly in the Video Ram due to its huge size. Here they need to switched among Virtual Memory (HDD) then to Main Memory (System Ram) and then to Video Ram (GPU Memory), resulting huge I/O penalty.
So i think now you guys know why Computing performance is important.
GCN and Keplar
Now i will conclude my article with a short overview on two main GPU architecture used these days : GCN and Keplar
GCN Architecture(AMD):
The building block of a GCN architecture is Compute Engine. So we will just discuss the basic design of a compute Engine.
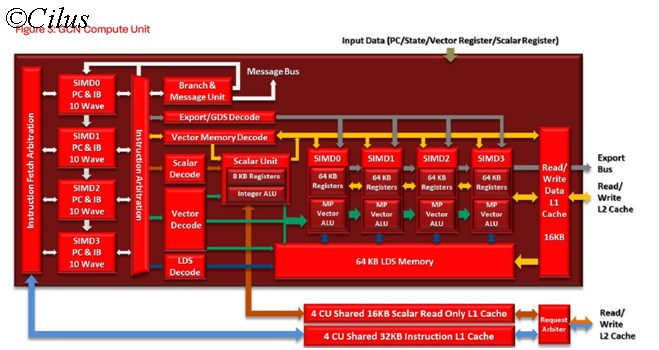
A Compute Engine or Compute Unit of GCN is comprised of 4 SIMD units, each with their own execution units and 64KB Register cache, one Scalar unit (with 8KB register cache and Scalar unit), separate Vector and Scalar Decode engine, a dedicated Branch prediction unit which predicts the conditional jumps (example: if i>0 then C = A + B Else C= A-D; A,B,C,D being Vectors). Also a 64 KB LDS memory is shared by all the four SIMD unit. A Read-Write unit is present which performs the read from memory and write back to memory operations. Each of the SIMD unit has 16 Vector execution unit, totaling 64 Vector Execution unit per CU. In other words, a single CU can perform a single operation over 64 data simultaneously. Now if you compare this design with the block diagram of the Vector Processor, you will find lots of similarities; in fact a single CU looks like a complete vector Processor which can perform a single operation over 64 data items simultaneously. This is the main advantage of GCN design as each of the CU can perform its operations independently without the help from other components as everything is placed inside a single CU.
As a result, if the CU count is increased, both the Graphics processing performance as well as the Compute performance will be increased proportionally.
Also, in the block diagram, you are seeing a new term called Wave or Wavefronts, which without going into details, can be considered a Thread for GPU. A wavefront can have maximum of 64 data items but they can come from a single operation (one operation to be performed over 64 data items) or from multiple operations ( 4 different operations to be performed, each over 16 data items, totaling 64 data-items).
As shown in the picture, 10 Wavefronts, each with 64 Data items, are available for each of the SIMD units, resulting a total 40 Wavefront assignment or (40X64)=2560 work-item assignment for just a single CU. Then each of the SIMD unit will pick one Wavefront from the 10 Wavefront assigned to them, resulting simultaneous execution of 4 Wavefronts.
Now here comes the best part:-
Suppose SIMD 0 has 10 Wavefronts, W1 to W10, assigned to it. Now while executing W2, it is observed that W2 is dependent upon another wavefront W4, SIMD0 will just save the current state of W2 in the Register cache associated to it and then pick up W4 for execution. Once W4 is finished and the results are available, it will fetch W2 from the registers and start executing it from the point where it was stalled. This is very similar to the Out of Order execution of a CPU and a feature not present in previous VLIW design.
Kepler Architecture(Nvidia)

The building block of Kepler architecture is SMX or Streaming Multiprocessor. Each of the SMX unit is comprises of mainly 192 CUDA cores or Stream processors, 32 SFU or Special Functional Units, 4 Wrap Schedulers and 32 Load-Store units. Each of the 192 Stream Processor can perform operation over a single Data item, resulting maximum capability of performing a single operation over 192 data items. SFU can perform some special operations over the data.
Now one technical thing, just like Wavefront in case of AMD, Wrap is the term used by Nvidia to explain a thread. The Wrap schedulers schedules the threads to the available 192 stream processors and we have four of them to schedule a single SMX. So at a time, 4 Wraps or thread can be scheduled by a SMX unit, and each will be assigned to be executed by a cluster of (192/4) = 48 Stream Processors.
Now there are two problems with this approach, when compared to GCN :
1st: If the count of stream processors are increased inside a SMX, say from 192 to 216, although the Graphics processing performance will increase almost proportionately, the compute performance will not. Because here the number of schedulers remain same for the SMX, only 4 and now they have to manage 216 stream processors. So Wrap Scheduler’s performance also need to be increased.
2nd: Nvidia was facing problems from their Fermi design to integrate a scheduler which is optimized for both Graphics and compute performance. In GTX 480, that has been done which leaded to higher transistor counts and huge power consumption.
In Kepler, Nvidia didn’t optimize their Scheduler for compute performance. Instead they just have provided minimum features which can handle current generation texture, Pixel and Vertex operations of Games properly. It reduced the production cost, power consumption and heating issues but in a cost of terribly weak compute performance.
So there you have it..a few words on the GPU
Signing off
Suryashis aka Cilus
Have questions,comment etc? Discuss it here :